728x90
반응형
1. Anaconda Prompt 에 pip install scrapy 입력
참고) 아래는 이미 scrapy를 설치한 뒤라서 Requirement already satisfied라는 메시지가 뜸)

2. Scrapy 설치 후 scrapy startproject wikiSpider 입력
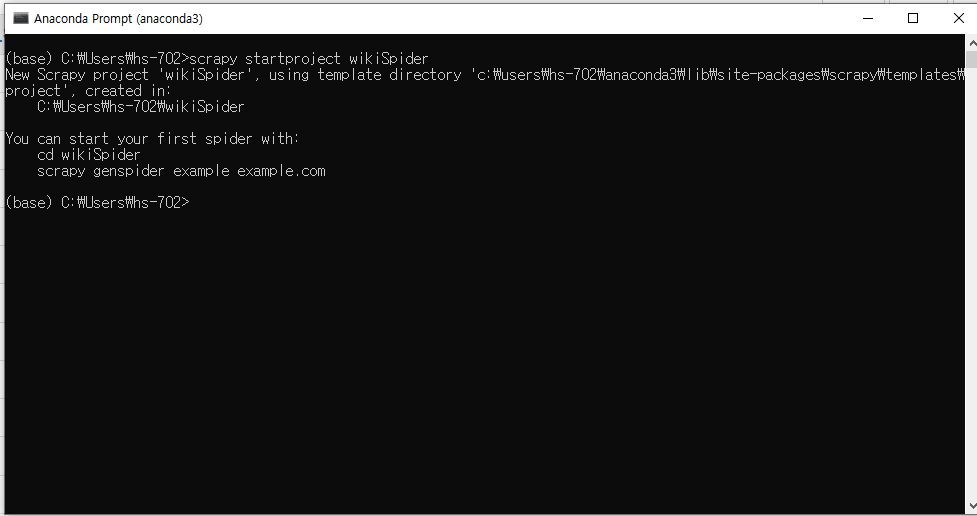
3. 생성된 wikiSpider 폴더 확인 후 하위 wikiSpider 폴더에 article 파이썬 파일 생성


4. Spider에 article.py를 불러온 뒤 python-scraping-master의 쥬피터노트북 article 코드를 복사>붙여넣기 후 저장
(저장하지 않으면 scrapy runspider article.py 를 실행할 때 No spider found in file 오류가 생김)

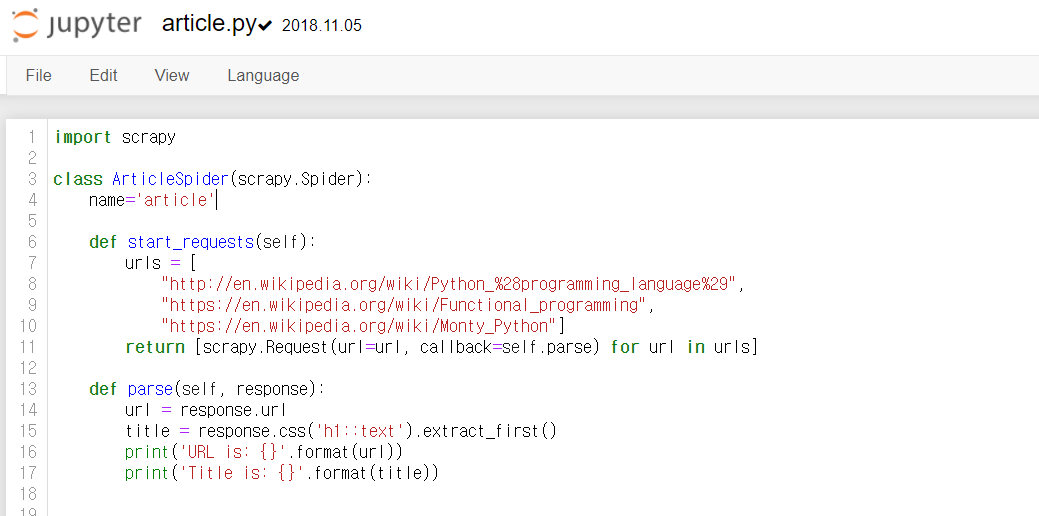
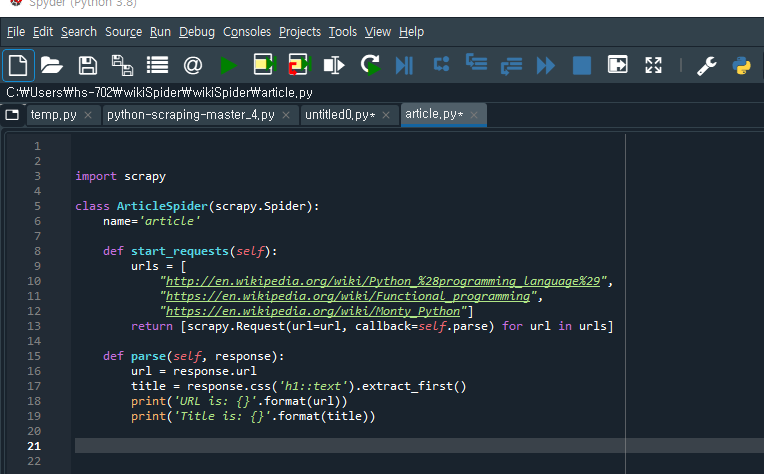
5. Anaconda Promt 창을 닫고 다시 열어서 scrapy runspider article.py 입력
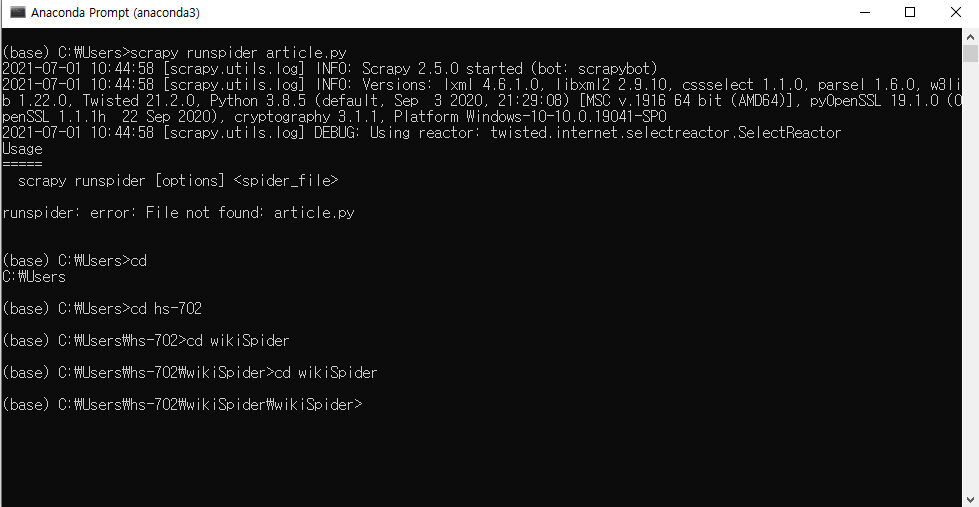
참고) article.py 가 저장된 경로를 지정해줘야 오류가 뜨지 않는다.

Spider 코드에 설정된 포맷대로 URL is :~~~~ Title is:~~~~ 이렇게 다음과 같이 print 됨을 확인할 수 있다.

728x90
반응형
'살콤아내 자기계발 > 파이썬' 카테고리의 다른 글
| 파이썬으로 배우는 웹 크롤러 6주차_Storing Data (pymysql 활용) (0) | 2021.07.06 |
|---|---|
| 파이썬으로 배우는 웹 크롤러 5주차_My SQL 설치 및 기본 사용 방법 (0) | 2021.07.02 |
| 파이썬으로 배우는 웹 크롤러 4주차_크롤링 실습 (특정 정보추출, 이미지 다운로드) (0) | 2021.06.30 |
| 파이썬으로 배우는 웹 크롤러 3주차_Selenium (0) | 2021.06.23 |
| 파이썬으로 배우는 웹 크롤러 2주차_BeatifulSoup (0) | 2021.06.18 |