- 452pg. 군집화 실습- 고객 세그먼테이션
http://archive.ics.uci.edu/ml/datasets/online+retail
UCI Machine Learning Repository: Online Retail Data Set
Online Retail Data Set Download: Data Folder, Data Set Description Abstract: This is a transnational data set which contains all the transactions occurring between 01/12/2010 and 09/12/2011 for a UK-based and registered non-store online retail. Data Set Ch
archive.ics.uci.edu
RFM 고객분석요소 기법 사용 (Recency, Frequency, Monetary Value)
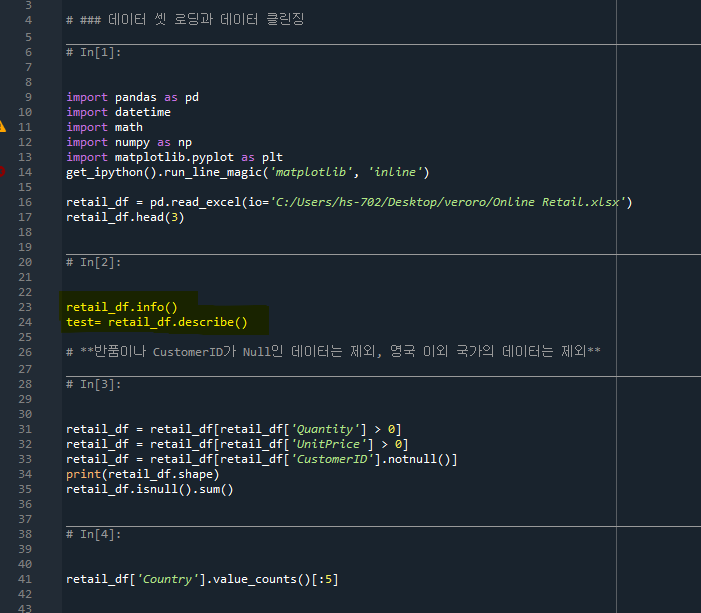
info함수를 통해 데이터를 대충 다음과 같이 파악할 수 있다.
- CustomerID에는 null값이 있다
- InvoiceDate의 데이터 타입은 datetime64 으로 (string과 유사하다)
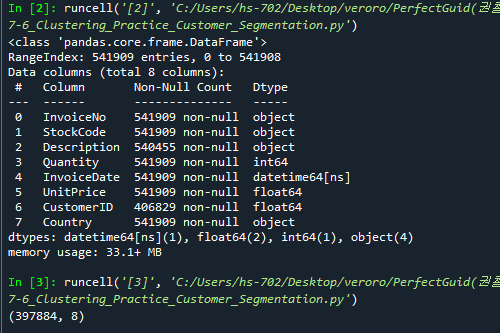
describe함수를 통해 Quantity, UnitPrice, CustomerID를 확인할 수 있다. (string값은 describe로 나타낼 수 없음)
- 31-32줄: 원본데이터에서는 quantity, unitprice가 음수로 나와서 31-33줄의 boolean 인덱스를 이용해서 데이터처리를 한다.
- 33줄: notnull을 통해 ID가 null이 아닌 데이터만 가져온다.
- 35줄: isnull( ).sum( )을 통해 null값인 데이터의 수를 모든 column별로 더한다.

- 47줄: "United Kindom" 자료만 원본데이터에 추려낸다.
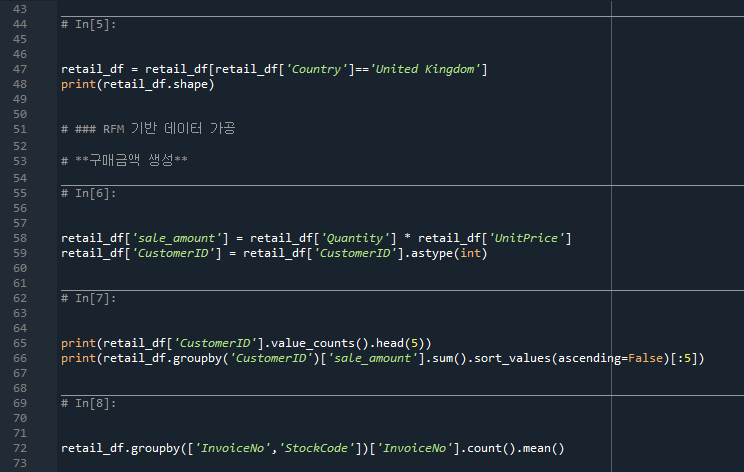
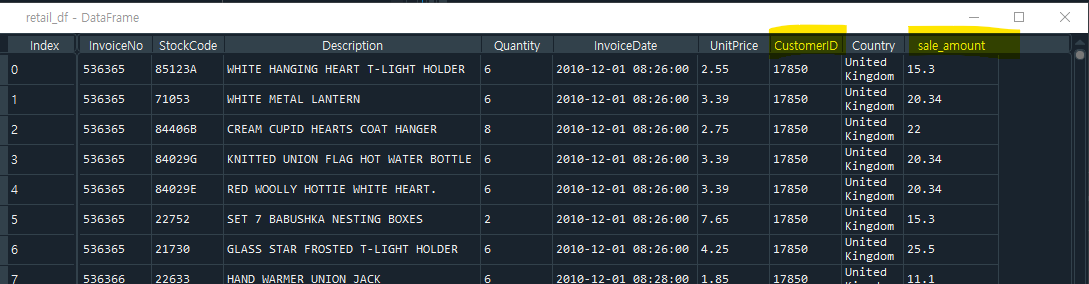
- 58줄: sale_amount라는 column을 만들고 quantity*unitprice를 합친 총구매금액(Monetary value)을 구한다
- 59줄: CustomerID를 float 값을 int값으로 변환한다. (기존에 CustomerID라는 column이 있어서 새로운 column이 생성되지는 않음)
- 65줄: CustomerID의 개수를 count한다 >>동일한 ID의 구매횟수를 체크한다.
- 66줄: CustomerID를 기준으로 sale_amount의 합(개별 주문별 총구매금액의 합)을 내림차순 정렬한다. (상위 5개만 보여줌)
- 72줄: InvoiceNo, StockCode를 기준으로 InvoiceNo 수의 평균값을 올림차순 정렬한다. (asending=True가 기본값)
>> 같은 주문번호내에 상품코드를 기준으로 정렬하는데, 상품코드의 개수를 count한다. (아래 설명있음)


참고) test2=retail_df.groupby(['InvoiceNo','StockCode'])['InvoiceNo'].count( ) 를 객체에 담아보았다.
하나의 주문별(InvoiceNo)로 상품(StockCode)들이 다를 수 있다.
예를들어 나의 주문번호가 100번이라고 할 때, 치약, 비누, 커피의 상품코드가 각각 1000, 1001, 2000 이며, 치약 2개, 치약1개, 치약 1개, 커피1개, 치약3개를 구매했다고 하자. (동일물건을 구매할 때 끊어서 구매한 경우)
[InvoiceNo].count( ) 는 null값이 아닌 값의 column의 개수를 말한다. (InvoiceNo에 Quantity가 와도 같은 mean값이 나와서 상관없음) 즉, 위의 예에서 치약을 3번 끊어구매한 경우 InoviceNo가 3이 나오게 된다. 즉, 이렇게 끊어구매한 경우의 평균은 아래와 같이 1.029...정도가 나오는데 이 말은 끊어구매한 경우가 별로 없다는 것이다. (count함수 앞에는 InvoiceNo가 아니라 Qauntity가 와도 상관 없다. 중복된 상품코드의 수를 세는 것이기 때문이다)
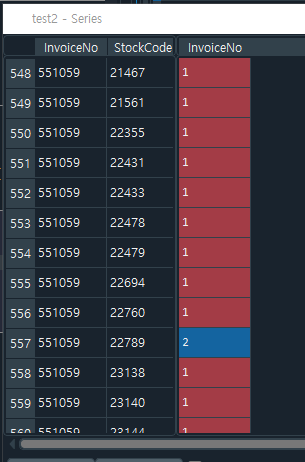

- 84줄: InvoiceDate는 가장 최근의 날짜(max), InvoiceNo는 동일인이 몇번 주문했는지(count), sale_amount는 총구매금액의 합을 의미한다.
- 89줄: cust_df에는 CustomerID를 기준으로 aggregations 함수를 사용한다. (여러개의 함수를 여러 열에 적용)
- 96줄: recet_index( )는 인덱스를 새로 부여함
- 105줄: cust_df에 Recenty column의 max값을 반환

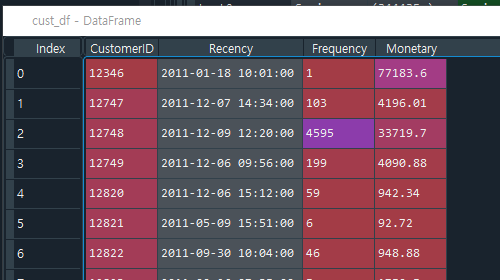
- 113줄: Recency의 원본데이터는 InvoiceDate 으로 datetime64[ns] 데이터 타입을 가진다. datetime은 가공없이 그대로 ML모델에 적용할 수 없으로 가공이 필요하다. (string값을 ML모델에 적용할 수 없듯이)
>> 즉, 유의미한 데이터타입인 숫자형 int형 으로 만들어야 한다. 그러기 위해서는 오늘 날짜를 기준으로 가장 최근 주문 일자(Recency)를 뺀 날자로 데이터 가공을 한다. (참고로 데이터가 2010.12.01.~2011.12.09.까지이므로 오늘 날짜는 현재 날자로 하면 안된다.) 결과적으로 '하루 전', '이틀 전'과 같은 숫자형으로 바뀌었으며, 이렇게 뺀 숫자값이 작을수록 최근의 데이터를 말한다.
- 114줄: 시간값과 시간값의 차이에 1일을 더한다. (2day 14hour의 데이터가 있을 수 있으므로)
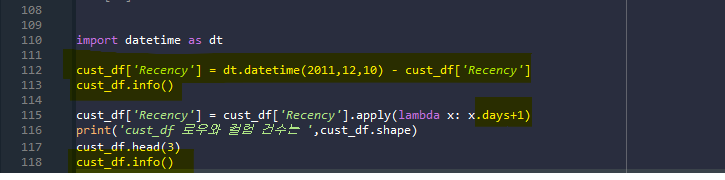
첫 번째 cust_df.info( )를 보면 Recency가 timedelta64로 바뀌었음을 확인할 수 있다.

두 번째 cust_df.info( )를 보면 Recency가 int64형으로 바뀌었음을 확인할 수 있다.



- 127줄: 히스토그램 3개를 그려보자.

히스토그램에서 100일 안에 한 번 정도 물건을 구매한 사람이 많음을 파악할 수 있다. 1000번 이내 구매한 사람이 다수를 차지했으며 전체 총 구매 금액이 25000불 이하로 지출한 사람이 가장 많았다.

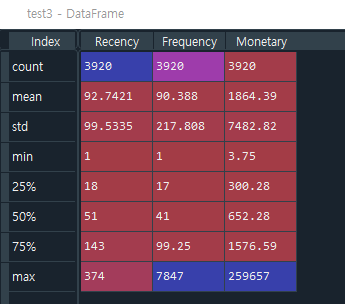
- 141줄: cust_df.describe( )를 test3객체에 넣어보면 Frequency, Monetary의 max값이 지나치게 큼을 알 수 있다. (중위값과 평균값의 차이가 너무 큼)
- 459pg. RFM 기반 고객 세그먼테이션
위의 온라인 판매 데이터세트는 히스토그램에서와 같이 군집화의 쏠림 현상이 나타나 skew(비대칭도)가 크다. (개인 뿐만 아니라 소매업체의 대규모 주문을 포함하므로) 왜곡된 데이터에는 StandardScaler로 평균과 표준편차를 재조정한 뒤 K-평균 군집을 적용해보자.


- 169줄: visualize_silhouette 로 군집을 시각화
실루엣 계수는 각 군집간의 거리가 얼마나 효율적으로 떨어져 있는지를 나타내는 지표이며, 0에 가까울수록 근처의 군집과 가깝고 1에 가까울수록 근처의 군집과 멀리 떨어져있음을 의미한다.

- 224줄: visualize_kmeans_plot_multi로 kmeans군집화를 시각화

앞서 정의된 함수 2개를 적용하면 다음과 같은 그래프를 볼 수 있다.

- 269줄: 실루엣 군집평가를 통해 3~5개로 군집화 할 때는 군집이 거의 이루어지지 않았음을 알 수 있다. 3~5개의 군집화에서 실루엣 계수 값이 아주 작은 몇몇 군집들은 outlier라고 볼 수 있다. (대량구매하는 소매업체)
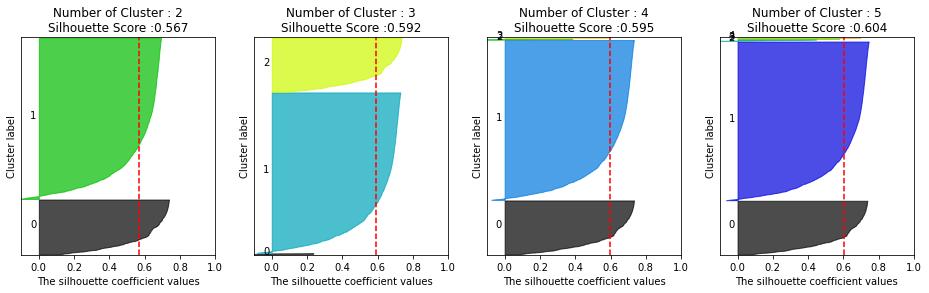
- 270줄: kmeans로 군집화 한 결과를 시각화한다. (kmeans 의 결과는 나름 괜찮아보일지라도 위의 실루엣계수를 보면 군집화가 잘 이루어지지 않았음을 확인할 수 있다)

군집의 개수를 늘린다고 해도 K-평균과 같은 거리기반군집화 알고리즘에서는 의미없는 군집의 결과값이 나온다. 이를 해결하기 위해 데이터값에 Log를 적용하면 더 나은 데이터를 도출할 수 있다.
- 296줄: Log변환을 통해 이전에 비해 (160줄과 비교했을 때) 실루어 스코어는 줄어들었음을 볼 수 있다.



>>비지도학습 알고리즘의 하나인 군집화의 기능적 의미는 숨어 있는 새로운 집단을 발견하는 것이며 전체 데이터를 다른 각도로 바라볼 수 있도록 돕는 것이다.
'살콤아내 자기계발 > 파이썬' 카테고리의 다른 글
| 파이썬으로 배우는 웹 크롤러 3주차_Selenium (0) | 2021.06.23 |
|---|---|
| 파이썬으로 배우는 웹 크롤러 2주차_BeatifulSoup (0) | 2021.06.18 |
| 파이썬 머신러닝완벽가이드 7주차_군집화 평균이동, GMM, DBSCAN (427pg) (0) | 2021.06.14 |
| 파이썬 머신러닝완벽가이드 7주차_군집화, 군집평가 (409pg) (0) | 2021.06.11 |
| 파이썬 머신러닝완벽가이드 7주차_차원축소 (382 pg, PCA, LDA, SVD) (0) | 2021.06.09 |