군집화의 쓰임: 영상처리, 이미지 처리
409pg. K평균 알고리즘
N개의 군집 중심점 설정
>> 각 데이터는 가장 가까운 중심점에 소속
>> 중심점에 할당된 데이터들의 평균 중심으로 중심점 이동
>> 각 데이터는 이동된 중심점 기준으로 가장 가까운 중심점에 소속
>> 다시 중심점에 할당된 데이터들의 평균 중심으로 중심점 이동
- K평균 알고리즘 장점: 쉽고 간결한 알고리즘으로 가장 많이 활용된다.
- K평균 알고리즘 단점: 거리기반 알고리즘으로 속성의 개수가 많으면 정확도가 떨어짐, 수행속도가 느리고 몇 개의 군집을 선택해야할지 가이드하기 어려움
사이킷런 KMeans 클래스
파라미터설정은 다음과 같다
- n_clusters: 군집화개수, 군집중심점의 개수
- init: 초기 군집 중심점의 좌표설정방식 (디폴트: k-means++)
- max_iter: 최대 반복횟수 (그 이전에 중심점 이동이 없으면 종료)
410pg. K-평균 예시

- 35줄: k-means++ 초기화 설정을 통해 3개의 군집으로 나눈다. 최대 300번까지 루프를 반복한다.

데이터가 어느 군집(0, 1, 2)에 속하는지 보여준다.
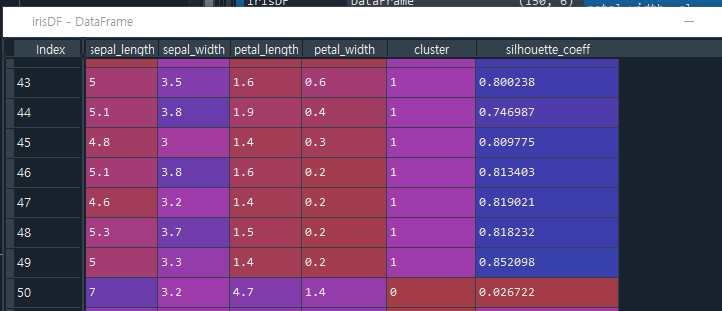
- 58줄: target과 cluster column별로 sepal_length의 수를 세어라. (target값은 label값/결정값, cluster값은 군집화 값)
- target값이 0과 1인 값인 데이터는 군집화가 잘 된 편이지만 target값이 2인 데이터는 군집화가 잘 안 된 편이다.

- 76줄: 4개의 축으로는 기하학적인 표현이 되지 않아서 2개의 축으로 차원축소한 뒤 scatter 그래프를 그림
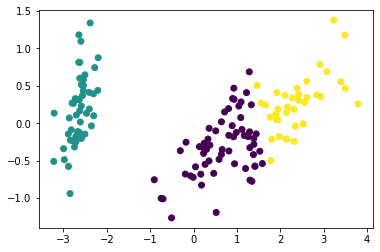
- 95줄: 0, 1, 2 cluster별로 scatter 그래프로 나타내기


- 415pg. 군집화 알고리즘 테스트를 위한 데이터 생성기 API
- make_blobs( )
- make_classification( )
- make_circle( )
- make_moon( )
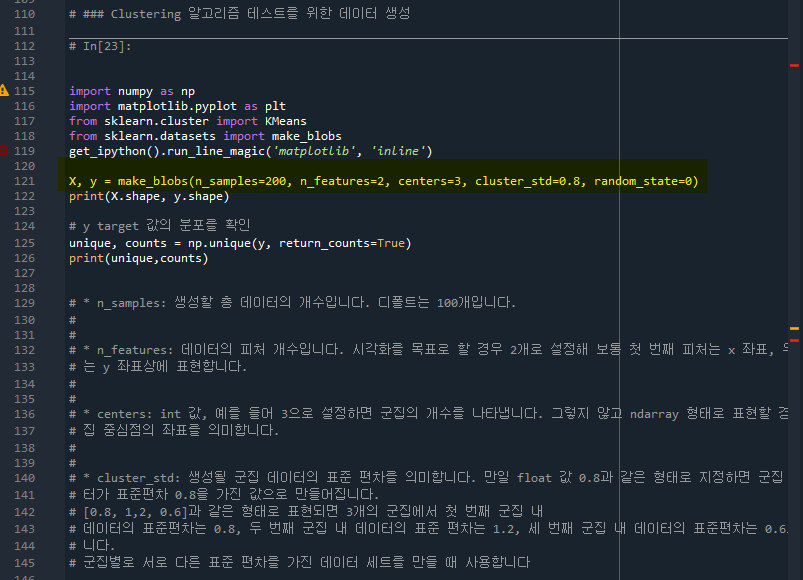
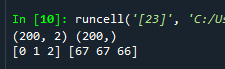
- 121줄: 데이터 개수 200개, 데이터 피처 2개, 군집 3개, 0.8 데이터 표준편차 설정
- 125줄: y안에 unique한 값이 몇개가 있는지 개수를 리턴해라 (unique는 0, 1, 2의 군집을 의미하고 counts는 각각의 군집에 몇개가 있는지 의미한다)
- 167줄: target_list에는 0, 1, 2의 군집값이 들어가 있다. 이를 scatter 그래프로 시각화한다.



- 186줄: KMeans로 데이터를 3개로 군집화
- 191줄: centers는 각 클러스터의 최종 중심값
- 198줄: center_x_y는 중심값의 좌표가 for문에 의해 각각 들어간다
- 203줄: 중심좌표 인덱스값을 각각 넣고 사이즈는 200으로 하는 군집화 scatter 그래프를 그린다.
- 205줄: marker= label값인 0, 1, 2로 표시한다
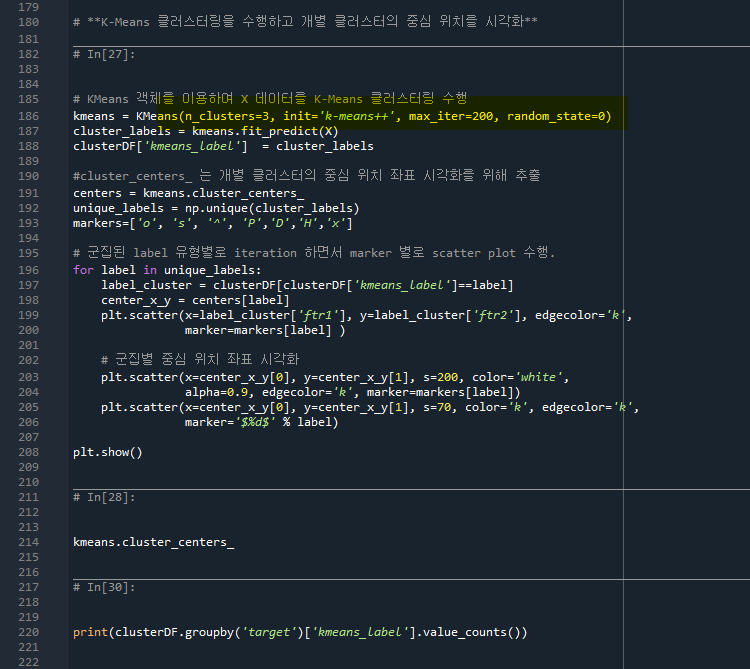
target값에 따라 kemans_label이 제대로 군집화되는 것을 볼 수 있다.



- 420pg. 군집평가 (Cluster Evaluation)
비지도학습이라도 군집화의 성능을 평가할 수 있는 대표적인 방법은 실루엣 분석이다.
실루엣분석 (Silhouette analysis): 각 군집간의 거리가 얼마나 효율적으로 분리돼 있는지를 나타낸다. (군집화가 잘 되었다는 것은 개별군집끼리 비슷한 여유공간을 가지고 떨어져 있음을 나타낸다) >> 실루엣 계수 (shilhouette coefficient)
실루엣 계수는 -1~1 사이이며 0에 가까울 수록 근처의 군집과 가까워 짐을 의미한다. (1로 가까워지면 근처의 군집과 더 멀리 떨어져 있음을, -값은 다른 군집에 데이터 포인터가 할당됐음을 뜻한다) 또한 전체 실루엣 계수의 평균값과 개별 군집의 평균값의 편차가 크지 않아야 한다.
s(i)= ( b(i) - a(i) ) / max ( a(i), b(i) )
a(i)는 동일 클러스터 내의 거리의 평균 (0보다 작을 수 없다)
b(i)는 타 클러스터와의 거리의 평균
max( a(i), b(i) ) 는 a(i), b(i) 중 큰 값
즉, 타 클러스터와의 거리가 크고, 동일클러스터 내의 거리가 작을 수록 좋다.
max( a(i), b(i) ) 는 a(i)가 0일 때 최대값이 1나온다. 또한 극단적으로 b(i)가 0이된다면 s(i)값은 -1이 나온다.
b(i)을 구할 때, 클러스터 A의 n번 데이터에서 가장 가까운 타 클러스터를 기준으로 한다. (420pg 그림 참고)
즉 클러스터 A의 데이터마다 가장 가까운 타 클러스터의 기준이 다르게 된다.
- 422pg. 군집평가 코드 예제
- 30줄: kmeans로 군집화 완료 (3개의 군집, 최대 300회)
- 32줄: irisDF에 'cluster' column을 생성함
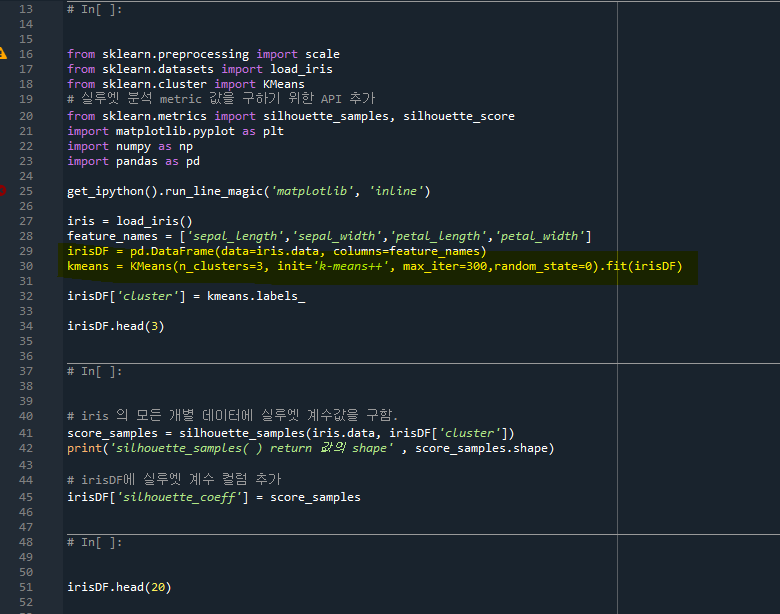
- 41줄: silhouette_samples 함수를 이용해 실루엣 계수값을 구하려면 각 데이터가 어떤 cluster에 속하는지 알아야 한다. 그래서 irisDF['cluster']값이 필욯다. 즉, silhouette_coeff는 각 데이터별의 실루엣 계수 S(i)값을 의미한다.
- 65줄: silhouette 계수의 히스토그램
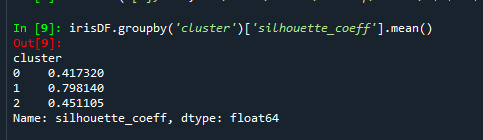
- 71줄: 개별군집의 실루엣 계수 평균값의 편차가 크지 않아야 한다는 조건을 만족시키기 위해 확인한다. 'cluster'를 기준으로 groupby를 하는데, 이에 대한 silhouette_coeff의 평균이다. 즉 0, 1, 2 label의 군집의 실루엣 계수 평균이다. (F9를 눌러서 확인)



- 136줄: make_blobs를 통해 500개 샘플, 2개 피처, 군집 4개, 각 샘플의 표준편차 1의 (4 클러스터 된) 데이터 샘플을 얻는다. (아래 iris데이터와는 상관없는 그냥 아무 랜덤데이터를 생성한다)

- 139줄: 위에 정의된 visualize_silhouette함수를 사용해서 클러스터를 2, 3, 4, 5로 나눌 때 실루엣 계수의 변화를 보고 가장 합리적인 실루엣 계수를 찾는다.

즉 빨간점선 (전체 실루엣계수의 평균값)이 크면 좋지만, 개별 군집(색깔별로 나뉘어진 실루엣계수)의 표준편차가 크지 않는 그래프를 찾아라. cluster 수가 2인경우, 0과 1클러스터의 데이터 분포 차이가 큰 편으로 적절하지 않다. (0번 클러스터는 상대적으로 실루엣계수가 낮다. 즉, 군집별로 차이가 큰 편이다) 그런데 cluster 수가 4인 경우 클러스터별로 고르게 비슷한 실루엣계수를 가지고 있어서 적절하다고 판단할 수 있다.

마찬가지로 iris.data를 이용해서 적절한 실루엣 계수를 찾아보면 2개의군집이 가장 좋아보인다.

'살콤아내 자기계발 > 파이썬' 카테고리의 다른 글
| 파이썬 머신러닝완벽가이드 7주차_고객 세그먼테이션 실습(452pg) (0) | 2021.06.16 |
|---|---|
| 파이썬 머신러닝완벽가이드 7주차_군집화 평균이동, GMM, DBSCAN (427pg) (0) | 2021.06.14 |
| 파이썬 머신러닝완벽가이드 7주차_차원축소 (382 pg, PCA, LDA, SVD) (0) | 2021.06.09 |
| 파이썬 머신러닝완벽가이드 7주차_차원축소, 선형변환, 공분산, PCA (377pg) (0) | 2021.06.08 |
| 파이썬 머신러닝완벽가이드 7주차_최종실습 (0) | 2021.06.08 |