183pg. 분류의 개요
- 지도학습은 label값 (명시적 답)이 주어진 상태에서 머신러닝 알고리즘으로 학습해 모델을 생성하고 이 모델을 통해 미지의 label값을 예측하는 것이다. 지도학습의 대표적인 유형에는 분류(Classification)가 있고, Baive Bayes, Logistic Regression, Decision Tree, Support Vector Machine, Nearest Neighbor, Neural Network, Ensemble 등의 머신러닝 알고리즘으로 구현할 수 있다.
- 앙상블 방법: 서로다른/같은 머신러닝 알고리즘을 결합한 방법으로 정형데이터의 예측분석영역에서 높은 예{측성능을 가지고 있다. 기본적으로 Decision Tree알고리즘을 사용하며, 앙상블 방법은 Bagging(Ex.Randon Forest)/Boosting(Ex.Gradient Boosting)방식으로 나뉜다.
- 결정트리 Decision Tree: if/else기반이며, 규칙노드(Decision Node)-리프노드(Leaf Node)-서브트리(Sub Tree) 구조로 되어있다. Depth가 깊어질 수록 예측정학도가 낮아지므로 이를 예방하기 위해서는 균일하게 Split해야 한다. 결정노드는 가장 균일도가 높은 데이터 세트를 먼저 선택하도록 규칙 조건을 만든다. (엔트로피를 이용한 information Gain지수, 지니계수가 있다.) 결정트리모델은 정보의 '균일도'룰을 기반으로 하여 시각화가 가능하고 데이터전처리가 필요하지 않는다.
- 결정트리 파라미터: 결정트리 알고리즘에는 DecisionTreeClassifier, DecisionTreeRegressor 클래스가 있으며 둘 다 min_samples_split, in_samples_leaf, max_features, max_depth, max_leaf_nodes의 파라미터를 공통으로 사용한다.
Ex) 지니계수 예시
- 지니계수는 불평등 지수인데, 파이썬에서는 불평등 지수가 높아져야 (지니계수가 작아져야) 분류의 정확성이 높아진다고 볼 수 있다. (한쪽으로 값을 몰아가기 때문)
- 아래의 def gini(p), def entropy(p), def error(p)는 2진분류를 가정하고 쓴 코드임


190pg. Graphviz 결정트리모형 시각화
Graphviz를 다운받은 뒤 (setup 시 path설정을 중간으로 하고 설치) Anaconda command에서 pip install graphviz를 입력해 인스톨한다. 그리고 Anaconda에서 다음 명령어를 친다.

그러면 지정경로에 tree.dot이라는 파일이 생성된다. g=graphviz.Source(dot_graph)를 받아 다음 4개의 코드를 입력한다. (책에 없음)
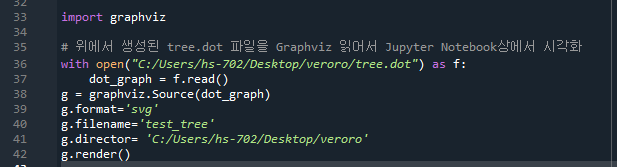
만약 Path 에러가 뜬다면 Anaconda를 다시시작하면 된다. 다시 실행 후 지정경로에 test_tree.svg라는 파일이 생성된다.


petal length, petal width는 column이름을 말한다. 만약 29줄에서 class_names, feature_names를 삭제하면 다음과 같이 레이블 이름정보가 시각화에서 사라지게 된다.

195pg
min_samples_splits=x
자식노드로 분할할 수 있는 최소한의 샘플 데이터개수는 x개임을 의미함.
Ex) min_samples_splits=4 이면 샘플데이터가 (0,2,1)개일 때 자식노드로 분화할 수 없다.
min_samples_leaf=x
leaf노드가 될 수 있는 조건은 디폴트로 1이지만, 값을 설정하면 리프노드가 될 수 있는 샘플데이터 건수의 최소값을 말한다. 즉, 샘플 데이터개수 x개를 만족하고 한쪽으로 몰릴 때 leaf노드가 될 수 있음을 의미함.
Ex) min_sampels_leaf=2이고, sample=7이라면 2와 5개로 나누어질 수가 없다.
둘의 차이는 거의 없다. 만약 샘플수가 4인데, splits=3, leaf=4의 값을 준다면? leaf=4이므로 멈춘다.
만약 샘플수가 4인데 splits=4, leaf=4라면? splits=4이므로 멈춘다.
198pg. feature importance
%matplotlib inline 파이선 코드가 아니라 주피터노트북에서 사용할 수 있는 매직코드이다.
(스파이더에서 에러가 발생할 수 있음>> get_ipython().run_inline_maginc으로 바꿔줌)
결정트리 과적합(Overfitting)
분류용 가상데이터를 생성해주는 make_classification( ) 에서 n_feature는 독립변수의 수, n_informatives는 종속변수 데이터와 상관있는 독립변수의 수, n_classes는 종속변수의 레이블데이터 개수, n_clusters_per_class는 한 클래스에 들어간 cluster(군집)의 수를 의미한다.
참고) feature데이터 종류가 2개이면 2차원 데이터로 나타낼 수 있다. (feature데이터 종류가 3개라면 3차원 그래프로 나타낼 수 있다. 그 이상은 시각화가 불가능)
plt.scatter ( ) 에서 같은 label 은 y_labels(같은색깔)로 표시가 된다. marker는 표시하는 모양을 말한다.

200pg. visualize_boundary( )함수

학습시킨 estimator(model), X_features, y_labels를 변수로 넣는다. xlim, ylim의 start, end는 x축, y축의 최소/최대값을 말한다.
model.fit(x,y)은 x, y값에 맞춰 모델학습시킴
meshgrid, linesplace, contour에 대해 알아보자
linspace(xlim_start, xlim_end, num=200) >> x값의 최소, x값의 최대까지 동일 비율로 200개의 데이터를 생성한다.
참고) range(0, 100, 0.1) >> 0에서 100까지 0.1간격으로 1000개의 데이터가 생성된다.
meshgrid에서 xx는 row는 같고 column값만 다른 값(xlim의 최소-최대값) yy는 column은 같고 row는 다른 값(ylim의 최소-최대값)을 리턴받는다. 즉, xx는 row방향으로 데이터를 yy데이터의 사이즈만큼 복사하고 yy는 column방향으로 데이터를 xx데이터의 사이즈만큼 복사한다.
Z=model.predict는 make_classification을 이용한 좌표로 학습시킨 어떤 예측값을 말한다. (make_classification은 기본적으로 100개의 데이터를 이용하는 모델을 만든다)
xx.ravel( ), yy.ravel( )는 데이터를 다음과 같이 1차원데이터로 펴주는 역할을 한다.

np.c_[ ] 는 xx.ravel( ), yy.ravel( )을 묶어주는 역할을 한다.


meshgrid로 만든 200x200의 변수 2개를 잘 조합하면 200x200 좌표 값에 다 들어간다. 즉 xx, yy의 4만개의 좌표값들이 조합되어 Z에서는 예측값이 4만개가 나온다.



이를 xx.shape를 통해 다시 200x200 shape로 만든다. 즉 Z는 모든 좌표에 대한 예측값이다. 이를 가지고 만든 contour 등고선은 다음과 같다. 뒤의 배경색은 predict값을 의미한다.


빨=0, 초=1, 파=2

이를 통해 overfitting유무를 알 수 있다. 중간에 라인이 있는데, 이러한 라인은 엄격한 분할기준으로 데이터가 학습데이터에 최적화된 overfitting 상태임을 말한다. (outlier, 즉 이상치까지 분류하게 되기 때문)
아래 in_samples_leaf 설정을 두고 학습을 시켜보자.

그러면 다음과 같이 구분이 명확해진다. overfitting이 완화되어 데이터세트의 정확도를 높일 수 있다.

'살콤아내 자기계발 > 파이썬' 카테고리의 다른 글
| 파이썬 머신러닝 완벽가이드 4주차 정리 (분류 211pg~, 앙상블학습) (2) | 2021.05.12 |
|---|---|
| 파이썬 머신러닝 완벽가이드 4주차 정리 (분류 202pg~) (0) | 2021.05.11 |
| 파이썬 머신러닝 완벽가이드 3주차 정리 (평가 175pg, Diabetes 실습) (0) | 2021.05.04 |
| 파이썬 머신러닝 완벽가이드 3주차 정리 (평가 147pg~) (0) | 2021.04.30 |
| 파이썬 머신러닝 완벽가이드 2주차 정리 (사이킷런 131pg, 타이타닉 생존자 예측) (0) | 2021.04.29 |