202pg. UCK HAR Datasets.zip를 다운받고 실습
archive.ics.uci.edu/ml/datasets/Human+Activity+Recognition+Using+Smartphones
UCI Machine Learning Repository: Human Activity Recognition Using Smartphones Data Set
Human Activity Recognition Using Smartphones Data Set Download: Data Folder, Data Set Description Abstract: Human Activity Recognition database built from the recordings of 30 subjects performing activities of daily living (ADL) while carrying a waist-moun
archive.ics.uci.edu

데이터를 분리하는 방법에는 쉼표, 공백 등이 있다. sep='|s+'는 공백, 앞에있는 키워드가 반복될 수 있다는 뜻으로 데이터를 분리한다.
features.txt파일에는 column명이 중복되어 있으므로 데이터전처리 후 DataFrame에 로드해야 한다. (column명은 값을 구분하는 인덱스의 기능이 있으므로 고유해야 함)

column_index는 중복되는 column_name의 수를 말한다. (1은 중복되는 값이 없다는 뜻)

적어도 42개의 Column_name이 중복되어 있다.

중복된 Column_name에 _1, _2이렇게 이름을 새로 만든다.

.cumcount( ): 중복된 feature명에 새로운 number를 부여한다.

.reset_index( ): 인덱스번호를 새롭게 부여 (test11)

pd.merge( ): 특정 키값으로 데이터프레임을 연결하는 것. how 파라미터는 outer/inner가 있다.
- outer: 합집합
- inner: 교집합
참고) concatenate( ): 물리적(축방향)으로 데이터프레임을 연결하는 것
데이터 구조를 보기 위해 코드를 잠깐 수정한다. (노란부분 추가)


다음을 merge할 때 key값을 설정하지 않으면, 서로가 가지고 있는 중복된 column name을 기준으로 한다.
즉, 여기에서는 중복되는 index를 기준으로 붙여준다.

비로소 new_feature_name_df가 만들어진다.
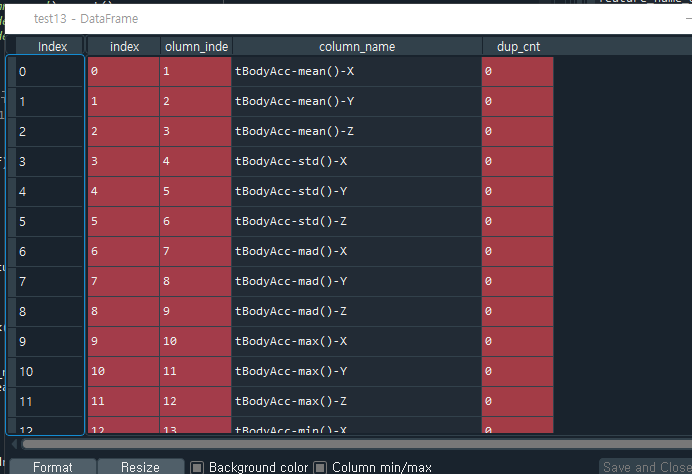
(lambda x : x[0]+'_'+str(x[1]) if x[1] >0 else x[0] , axis=1)
lambda함수에서 x는 개개의 row값들이 들어간다. x[0]은 column_name의 element들을 의미하고, x[1]은 그 옆에 있는 dup_cnt의 element를 의미한다. 만약 dup_cnt값이 0보다 크면 (중복되는 column_name이 있다면) column_name에 _ (언더바) _ 숫자 형식으로 column_name이름을 새로 붙인다. 그렇지 않으면 x[0]값 (오리지널 column_name)을 반환한다.
205pg. Train/Test 데이터 Split하기
- isna( ) : 결측값의 수

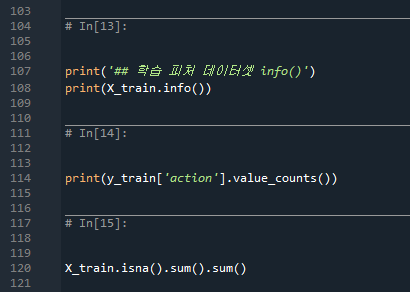

결과
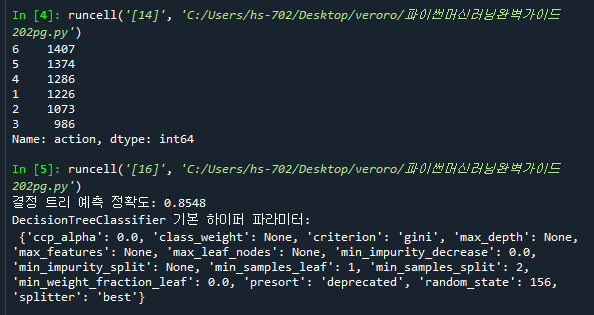
DecisionTree에서 criterion의 설정값을 바꿀 수 있음. (gini 계수가 변화함)
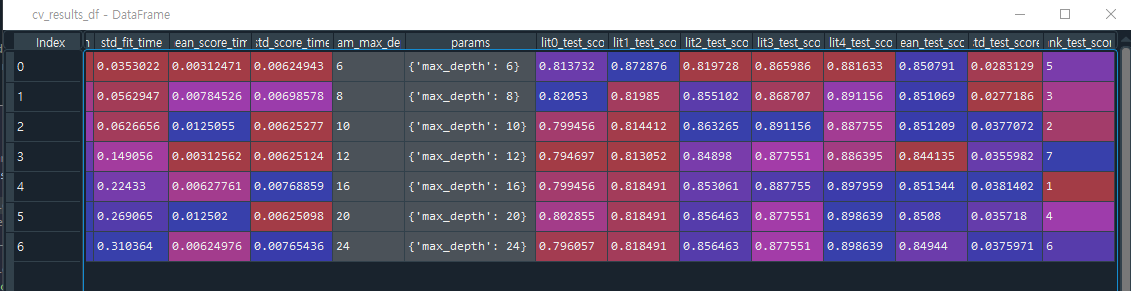
207pg. 교차검증 GridSearchCV를 이용해서 최적 파라미터 구하기


max_depth가 16일 때 최적의 parameter값이다.
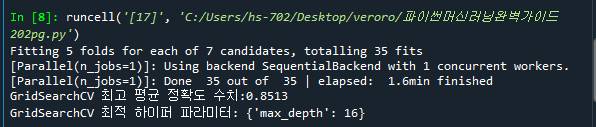
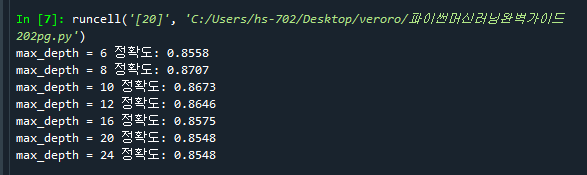
208pg. 교차검증을 이용하지 않은 최적의 parameter값 찾기

verbose는 돌아가는 함수의 현재상태 메시지를 출력할지 결정하는 파라미터

여기서는 max_depth가 8일 때 최적의 값이다.

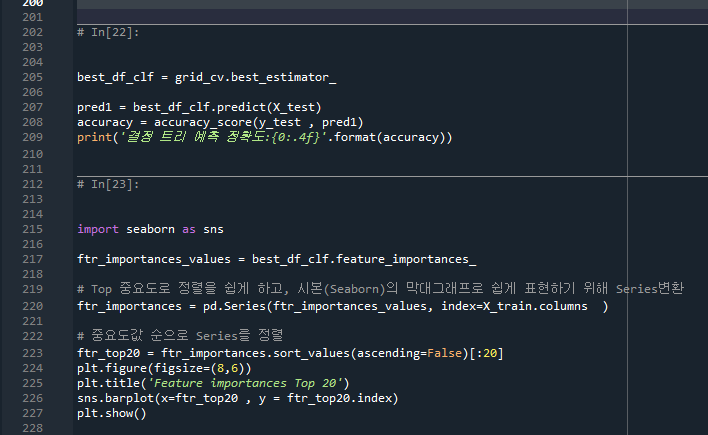
참고) DecisionTree의 윗부분에 있을수록 기여도가 높음


'살콤아내 자기계발 > 파이썬' 카테고리의 다른 글
| 파이썬 머신러닝 완벽가이드 5주차 정리 (분류 214pg~, 보팅분류기, 랜덤포레스트, XGBoost) (0) | 2021.05.17 |
|---|---|
| 파이썬 머신러닝 완벽가이드 4주차 정리 (분류 211pg~, 앙상블학습) (2) | 2021.05.12 |
| 파이썬 머신러닝 완벽가이드 4주차 정리 (분류 183pg~) (0) | 2021.05.07 |
| 파이썬 머신러닝 완벽가이드 3주차 정리 (평가 175pg, Diabetes 실습) (0) | 2021.05.04 |
| 파이썬 머신러닝 완벽가이드 3주차 정리 (평가 147pg~) (0) | 2021.04.30 |