머신러닝은 데이터 가공/변환, 모델학습/예측, 평가로 구성됨.
성능평가지표(Evaluation Metric)은 분류/회귀모델에 따라 달라진다.
- 회귀: 실제값과 예측값의 오차 평균값을 성능평가지표로 갖는다.
- 분류: 분류는 이진분류/멀티분류로 나뉘며, 정확도(Accuracy), 오차행렬(Confusion Matrix), 정밀도(Precision), 재현율(Recall), F1스코어, ROC AUC의 성능평가지표를 갖는다.
1. 정확도 Accuracy
참고) 정확도와 재현율은 trade-off(상충)관계이다.
- 새로만든 MyDummyClassifier 클래스에 BaseEstimator를 상속한다.
- fit는 pass를 하기 때문에 아무것도 학습하지 않는다.
- predict는 test 데이터의 feature값이 들어간다.
- X.shape[0]: X는 test 데이터의 feature값이다. .shape[0]은 X test데이터 모양이 179x8인데 그 튜플 중 첫번째 element- 이므로 891이 나온다. 즉 test데이터의 row의 개수값을 말한다.
- np.zeros함수를 사용해서 이를 0으로 채우면 mypredictions에서 볼 수 있다.
- iloc 위치기반 인덱싱을 말하는데, 1(남자)일 경우 pred[i]이 0이다.

질문) fit에서 3개의 변수가 들어가는 이유?
class를 생성할 때 새로운 객체가 만들어지는데, 이 때 def fit에 자동으로 이 객체의 속성을 반영하는 self가 들어가게 된다.



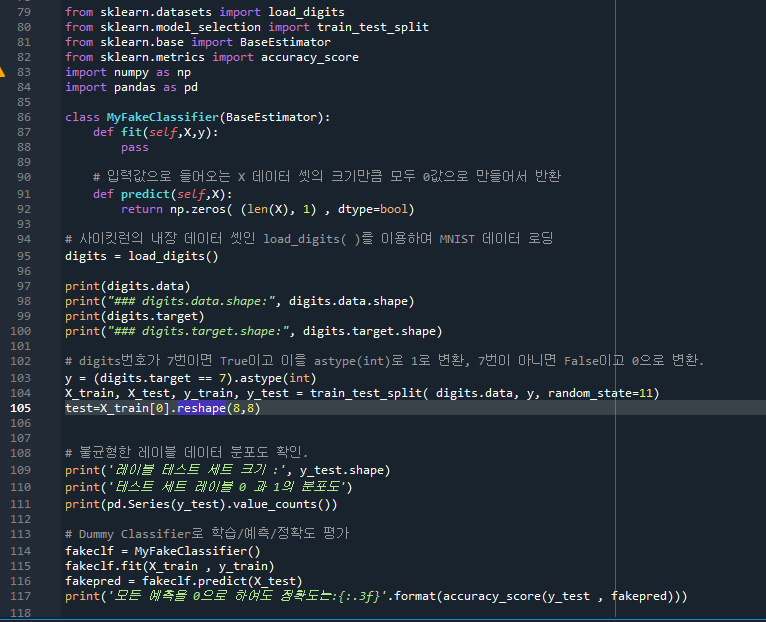
150pg. 손글씨 MNIST 데이터세트
- def fit는 X, y값을 받아서 아무학습을 하지 않는다. (pass)
- np.zeros( (len(x), 1) input값으로 들어온 데이터 사이즈만큼 0을 채운 데이터를 만들어라.
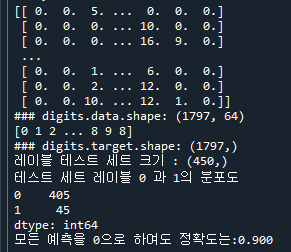
X_train은 450x64 데이터 사이즈를 가지고 있는데, len(x)는 row의 개수로 450개를 말한다. 즉, 450x1에 해당되는 shape 공간에서 0을 다 채운 데이터를 만들게 된다. np.zeros 의 파라미터 dtype을 bool로 설정한다. 0이면 False, 1이면 True.
- fakepred에는 전부다 false가 들어간다. y-test와 fakepred를 비교하니 정확도가 90%가 나왔다.
test=X_train[0].reshape(8,8)태로 바꿔본다. 그러면 test에는 일렬로 된 X_train의 0인덱스 줄에 있는 데이터가 다시 원상태로 돌아온다. 아래 test에 있는 데이터는 숫자 2와 비슷하다. 실제 target값인 y도 숫자 2임을 나타낸다.

y= (digits.target==7) 이라면 y에는 7에 True라는 boolean값이 담긴다. (나머지는 Flase값이 담김)
이 후에 .astype(int)를 추가하면 True는 1, False는 0값이 담긴다.

그러나 정확도 평가 지표는 불균형한 레이블 데이터 세트에서는 성능수치로 사용하면 안된다.
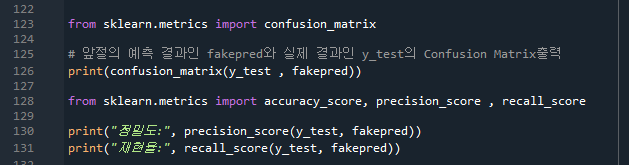
152pg. 오차행렬 Confusion matrix
- 실제클래스(Actual calss) x 예측클래스(Predicted class)의 TN, FP, FN, TP 오차행렬 4분면으로 분류모델 예측 성능의 오차를 평가
- 이 값들을 통해 정확도(Accuracy) 뿐만 아니라 정밀도(Precision), 재현율(Recall)값을 알 수 있음
- confusion_matrix( ) API 사용
- 정확도= (TN+TP)/(TN+FP+FN+TP) >>> 전체 예측한 대상 중에 실제로 정확히 예측한 데이터의 비율
Ex) 위의 예문에서 숫자 7을 제외한 나머지 bool값을 0 (False)로 설정해놨기 때문에, 정확도는 TN과 FN만 고려하게 된다.
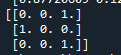
정밀도와 재현률에는 실제값과 fakepred라는 예측값을 변수로 한다.

153pg. 정밀도, 재현율 (정밀도와 재현률은 trade off 관계이다)
- 정밀도= TP/(FP+TP) >>> 예측을 Positive로 한 대상 중에 예측과 실제값이 Positive로 일치한 데이터의 비율로 precision_score( ) API로 제공.
- 재현율 = TP/(FN+TP) >>>실제값이 Positive인 대상 중에 예측과 실제값이 Positive로 일치한 데이터의 비율로 recall_score( ) API로 제공.
Ex) 재현율이 중요한 경우: Positive(실제 양성)를 Negative(음성)로 잘못 판단하면 손해가 더 큰 경우로 암 판단, 보험사기 적발 모델은 재현율이 중요함. FN(type2 error)을 낮춰 재현율을 높여야 한다.
Ex) 정밀도가 중요한 경우: Negative(실제 음성)을 Positve(양성)로 잘못 판단하면 손해가 더 큰 경우로 스팸메일 판단 모델은 정밀도가 중요함. FP(type1 error)를 낮춰 정밀도를 높여야 한다.



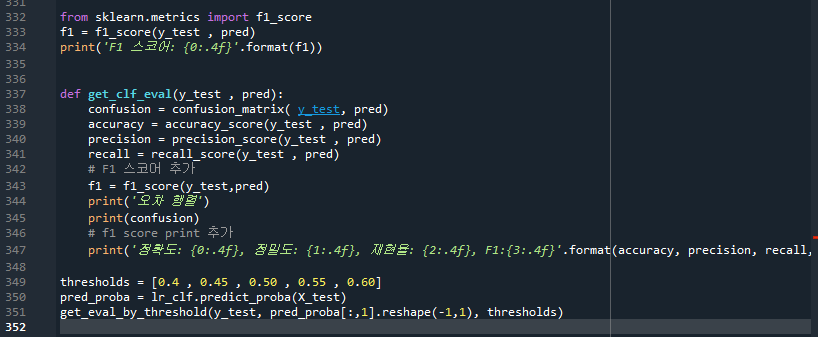
- get_clf_eval( ) : confusion matrix, accuracy, precision, recall등의 평가를 한꺼번에 호출하는 함수
159pg. 정밀도/재현율 트레이드 오프
- predict_proba( ) 개별 데이터별로 예측 확률을 반환하는 메서드 (예측값을 산정하기 위한 확률을 반환)
오차분석 절차: train_test_split>>> fit >>> predict_proba >>> predict >>> 예측값

각 데이터의 각각의 생존확률이다. (1은 생존, 0은 사망, 두 경우를 합치면 확률이 1)
lr_clf라는 estimator에서 predict라는 함수를 사용.

pred_proba의 index 0의 경우 1(생존) 확률이 0.5이상이므로 pred는 이 값을 반영해서 index0을 생존했다(1)고 본다.

- np.concatenate 는 axis 축 방향으로 두 개의 데이터인 pred_proba, pred.reshape(-1,1)를 연결한다. axis=1이므로 column방향(오른쪽)으로 연결하게 된다. pred.reshape(-1, 1)은 column 1을 기준으로 행렬을 다시 reshape하는 것을 의미한다. reshape한 이유는pred_proba는 2차원인데(179,2) pred는 1차원데이터이다(179,)인데 두 데이터를 연결하기에는 차원의 개수가 맞지 않기 때문이다.


Threshold 수치를 조정해보자
- 결정 임곗값(Threshold)를 조정해 정밀도/재현율 수치를 변화시킬 수 있음
Binarizer라는 클래스를 호출해서 threshold가 1.1보다 작으면 0, 크면 1을 반환한다.

아래는 위와 비교했을 때 Binarizer 후에 fit을 바로 적용했다.
- Binarizer의 threshold를 custom값으로 넣는다 (0.5) 이는 pred_proba로 구한 값과 동일하게 나와야 한다. pred_proba는 기본 임계치가 0.5로 세팅되어 있기 때문이다.
- get_clf_eval은 평가관련 함수를 모두 모아놓은 함수다.

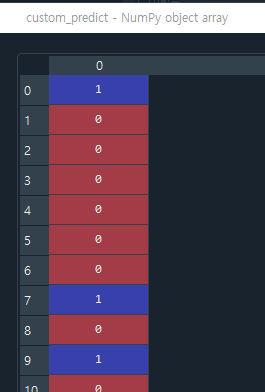
본격적으로 Binarizer라는 클래스의 threshold값을 0.5에서 0.4로 바꿔서 적용해보자

pred_proba는 변화하지 않지만 custom_predict의 값은 변화한다. get_clf_eval을 시행하면 다음과 같이 정확도, 정밀도, 재현률이 변화한다. (정확도는 떨어짐, 정밀도 떨어짐, 재현율 올라감)

- 분류결정 임곗값이 낮아질수록 Positive로 예측할 확률이 높아져서 재현율이 증가한다. (반대로 정밀도는 낮아짐)
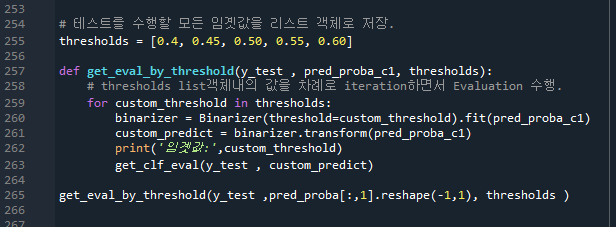
Binarizer 클래스를 이용해서 for문에 있는 threshold값을 차례대로 입력하여 정밀도, 재현율, 정확도 오차행렬의 경향성을 각각 보여준다.
pred_proba_1 는 1이 될 확률값만 가지고 온 데이터를 말한다.


165pg. precision_recall_curve 함수를 이용해보자
- precision_recall_curve는 thresholds값을 x축으로 놓고 precisions, recalls를 y축으로 놓는 그래프를 그린다.
- thr_index= np.arrage함수는 (0, 143, 15)의 값을 가진다. threshold.shape[0]가 143이기 때문! 즉, 0부터 142까지 15 간격으로 수치가 입력된다.
- np.round는 thr_index에 해당되는 threshold의 임곗값/precisions의 정밀도/recalls의 재현율 값을 소수점 2, 3자리까지 나타낸다.


- matplotlib을 호출해서 그래프를 그려보자
plt.plot(x축, y축, linestyle, label) >>> x축, y축은 same dimension을 가지고 있어야 한다. 즉, plt.plot([1,2,3], [4,5,6])은 되지만 plt.plot([1,2,3,], [4,5,6,7])은 안된다. plot.plot(thresholds, precisions[0:threshold_boundary], linestyle, label)에서 threshols의 개수와 precisions의 dimension 개수가 맞지 않아서 precisions에 index slicing을 해 준 것이다.


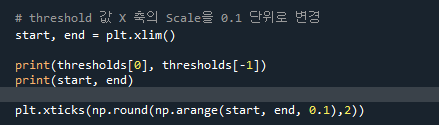
plt.xlim()은 x축정보인데 축의 최소값, 최대값을 받는 것이다.
plt.xticks는 x축에 표기되는 값들에 대한 정보이다. 0.1간격으로 소수점 2자리까지 표기.

- 정밀도와 재현율의 맹점
- 정밀도가 100%가 되는 방법: 확실한 경우만 positive로 예측, 나머지는 negative로 예측한다.
- 재현율이 100%가 되는 방법: 모든 경우를 positive로 예측한다.
168pg. F1스코어
F1스코어=정밀도와 재현율을 결합한 지표= 2*(precission*recall)/(precission+recall)
참고) WolframAlpha 계산기 활용
F1스코어가 커지기 위해서는 정밀도와 재현율이 비슷한 비율을 가지고 있어야 한다. 한 쪽 비중이 높아지면 F1스코어가 낮아진다. (이전에 precision_recall_curve 그래프에서 두 점이 교차하는 지점이 F1스코어가 가장 크다)
생각해보기) F1스코어가 높아졌는데, 정밀도와 재현율의 차는 벌어졌다. 왜 그럴까? 정밀도의 상승폭이 재현율의 하락폭보다 더 크기 때문이다. F1스코어는 case by case. (단, 정밀도나 재현율 중 한가지가 극단적으로 큰 경우는 좋지 않다)


169pg. ROC곡선과 AUC스코어 (이진분류 예측성능지표)
- ROC곡선(Receiver Operation Characteristic Curve, 수신자 판단곡선): X축 FPR(False Positive Rate)가 변할 때 Y축 TPR(True Positive Rate, 재현율, 민감도)의 변화를 나타낸다. FPR=1- TNR(True Negative Rate, 특이성)
- TPR, TNR은 클수록 좋고, FPR은 작을수록 좋다.
- roc_curve( ) API 사용
- AUC (Area Under Curve) 스코어: ROC곡선 밑의 넓이. ROC그래프가 직선에서 멀 수록 성능이 더 좋은 모델이다. 즉, 최대값 1에 가까울 수록 좋다. (보통 0.5 이상의 AUC값을 가진다)
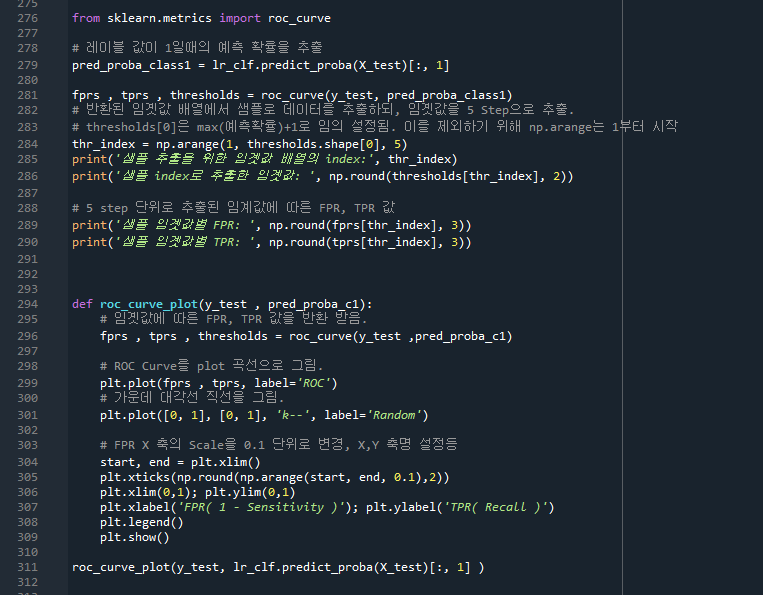

질문) 둘의 차이?
np.arange(1,thresholds.shape[0],5)
plt.xticks(np.round(np.arange(start,end, 0.1),2))
'살콤아내 자기계발 > 파이썬' 카테고리의 다른 글
| 파이썬 머신러닝 완벽가이드 4주차 정리 (분류 183pg~) (0) | 2021.05.07 |
|---|---|
| 파이썬 머신러닝 완벽가이드 3주차 정리 (평가 175pg, Diabetes 실습) (0) | 2021.05.04 |
| 파이썬 머신러닝 완벽가이드 2주차 정리 (사이킷런 131pg, 타이타닉 생존자 예측) (0) | 2021.04.29 |
| 파이썬 머신러닝 완벽가이드 2주차 정리 (데이터 전처리 118pg~, ) (0) | 2021.04.28 |
| 파이썬 머신러닝 완벽가이드 2주차 정리 (사이킷런 87pg~, ) (0) | 2021.04.27 |