319pg. 규제선형모델
가중치w값은 회귀모델의 기울기와 관련된다. 회기모형의 차수가 증가함에 따라 MSE를 낮추기위해 가중치w값은 필연적으로 커지게 된다. (기울기가 급격하게 변하는 방향으로 학습이 될 수 밖에 없다)
- 규제(Regularization): 비용함수에 alpha값으로 패널티를 부여해 회귀계수 값의 크기를 감소시켜 과적합을 개선하는 방식
- 비용함수목표= Min(RSS(W)+alpha* llWll^2)
- alpha값을 작게하면 비용함수 RSS(W)가 최소화 / alpha값을 크게하면 회귀계수 w가 감소한다.
*alpha값은 데이터 적합정도와 회귀계수 값의 크기 제어를 수행하는 튜닝파라미터를 말한다.
*llWll는 벡터값의 절대값을 말한다.
*RSS: 294pg 비용함수참고
321pg. 릿지회귀
- Ridge는 규제선형모델의 클래스이름 (L2규제 적용: RSS+alpha*lWl^2)
- 347줄: alpha값이 강할수록 w값이 커지는 것(차수가 커지는 것)에 대한 강한 규제를 적용한다.


- 362줄: alpha값에 따른 RMSE값은 다음과 같으며, 최적의 alpha값은 100이다. (alpha값을 늘려서 시험해봤는데 100이 최적이었음)


- 380줄: alpha값에 따른 맷플롯립 그래프 생성

- 389줄: ridge.fit를 시킨 다음 coeff에 시리즈데이터를 만든다. ridge.coef_는 규제값이 적용이된 비용함수를 최소화시키는 모델의 회귀계수를 말한다. 즉, 학습된 각 column에 따른 각각의 가중치w가 반환된다. X_data.columns는 각각의 column의 이름을 반환한다.

- 391줄: coeff_df이라는 DataFrame에 colname, 즉 alpha:+string이라는 column을 생성한다. 이 column에 coeff 데이터를 집어넣는다.

- alpha값을 커지면 전반적으로 가중치w 절대값이 작아지는 양상을 볼 수 있다.

- 324pg 라쏘회귀 (L1규제 적용: RSS+alpha*llWll)
- 423줄: Ridge, Lasso, ElasticNet이라는 모델을 이용한 for문
- 446줄: coeff_lasso_df에서 lasso_alphas를 넣어서 get_linear_reg_eval을 수행한다.

- 455줄: coeff_lass_df를 sort_column을 기준으로 내림차순으로 정렬

- 327pg. ElasticNet회귀
목표: RSS(W)+alpha2*llWll^2+alpha1*llWll 식을 최소화하는 W를 찾는 것 (라쏘회귀가 중요 피처만을 선택해서 다른 회귀계수를 0으로 만드는 문제때문에 이를 완화할 필요가 있음)
- alpha 파라미터 값은 alpha2+alpha1이다. l1_ratio는 alpha 1과 alpha2의 비율을 말한다.



- 329pg. 선형 회귀 모델을 위한 데이터 변환
- 선형모델은 Feature와 Target값 간에 선형의 관계가 있다고 가정하여 최적의 선형함수를 찾아내 결과값을 예측
- 스케일링/정규화 작업(StandardScaler, MinMaxSacaler, 다항특성적용, Log Transformation)을 통해 왜곡(skew)을 줄인다. 참고로 Target값은 Log Transformation을 일반적으로 적용함 (정규분포로 변환하면 원본으로 되돌리기 어렵기 때문)
- 494줄: input_data를 if문에 따라 표준화시켜주는 작업

- 520줄: sacle_methods 리스트에 있는 6개의 tuple element를 기반으로 for문을 돌린다. (만약 method=standard라면 p_degree=None이 들어간다)
- 524줄: get_linear_reg_eval으로 회귀값을 구한다. alphas파라미터를 이용해서, 스케일링된 데이터인 X_data_n에 Ridge모델을 적용한다.
- 결과적으로 로그변환이나 최소값/최대값 정규화+2차다항식의 경우가 가장 성능이 좋다.


-332pg. 로지스틱회귀 (LogisticRegression)
- 선형회귀방식을 분류에 적용하되 시그모이드 함수(sigmoid)를 이용해 분류를 수행하는 회귀이다. (Regression(회귀)임에도 불구하고 분류분석 알고리즘임)
- Tree분류는 지니계수를 낮추는 것, LogisticRegression은 RSS값(비용함수)을 낮추는 것이 모델링의 목적이다.
- 회귀의 선형/비선형은 가중치w의 변수에 따라 결정된다.
- 시그모이드 함수는 x값에 상관없이 y는 0~1사이 값을 반환한다. (자연/사회현상의 특정 확률 값은 대부분 선형이 아니라 S커브 형태를 그린다)
참고) 활성화함수 z=xw(x값과 가중치w의 내적) 를 S(x)에 적용해서 예측값을 도출한다. (즉 S(x)의 x에 z를 넣는다)
z가 커지면 분모가 증가해서 0으로 수렴하고 S(x)는 1에 수렴한다. z가 작아지면 분모가 감소해서 1로 수렴하고 S(x)는 0으로 수렴한다.


- 333pg에 이진분류데이터는 시그모이드 함수의 그래프로 잘 표현이 된다. 삼진분류와 같은 멀티분류도 마찬가지로 그래프화가 가능하다.
선생님 예시) 감, 귤, 배를 시그모이드 함수로 삼진분류하는 로지스틱회귀 모델을 만들어라.
다음과 같이 이진 분류한 3개의 모델을 만들어서 학습시킨다. 그러면 1과 0이 나오는 각각 확률을 구할 수 있다. 즉 감이될 확률, 귤이될 확률, 배가될 확률 (1이 나오는 확률)을 구할 수 있다.
해당 레이블 값만 1로 두고 나머지 레이블 값을 0으로 둔다. 모든 모델에 데이터를 넣어서 각각의 레이블이 1이될 확률을 구한 뒤, 1이 될 확률이 가장 큰 값을 각 반환한다. (멀티레이블에서 각각 뽑아낸 활성화 함수의 최대값이 나온 모델의 레이블을 분류 레이블로 선택한다.)
| M1 | M2 | M3 | |
| 감 | 1 | 0 | 0 |
| 귤 | 0 | 1 | 0 |
| 배 | 0 | 0 | 1 |
코드예제)


- 59줄: params에는 L2, L1 규제 설정을 하는 것이고 C는 규제강도를 조절하는 alpha값의 역수이다. 즉 0.01은 alpha값이 100임을 의미한다.
335pg. 회귀트리
- 데이터를 특정 기준으로 분할split하고 리프노드에 속한 데이터 값의 평균값을 구해 회귀 예측값을 계산한다.



- 125줄: models 리스트 안에는 estimator들의 class 객체 데이터 타입이 들어있다. (리스트 안에는 다양한 데이터 타입이 들어갈 수 있다)

- 데이터 사이즈에 따라 위의 결과값이 달라질 수 있다

- 143줄: reg.feature_importances는 tree기반의 알고리즘모델에서 어떤 feature가 이 tree를 만드는데 가장 결정적인 영향을 미치는가?이다. 해당 column의 feature importance값이 상대적인 수치로 나타낸다. 값이 클 수록 RegressorTree를 만들 때 결정적인 기여를 한 것이라고 볼 수 있다. 이를 내림차순으로 sort_value한다.
참고) tree기반 모델에서는 가중치 학습이 이루어지지 않는다. 어떤 특정 feature에서 MSE이나 RSS값을 최소한으로 하는 조건식을 만들어서 분류를 한다. (반면, regressor기반 모델에서는 가중치 학습이 주어진다)
-

이를 barplot으로 다음과 같이 나타낼 수 있다.
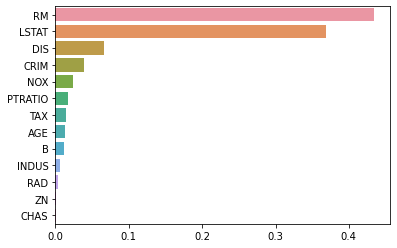
- 156줄: bostonDF에서 RM, PRICE라는 두 개의 column을 가져온다. 그리고 100개의 샘플을 랜덤하게 가져온다.

- 160줄: x축은 RM, y축은 PRICE인 scatter 그래프를 그려본다.
참고) bostonDF_sample.RM은 bostonDF_sample['RM']처럼 쓸 수 있다.

- 171줄: Tree기반 알고리즘에서 오버피팅을 줄이기 위해서는 depth, leaf node 조건 등을 완화시킬 수 있다. 이 또한 DecisionTreeRegressor에도 적용된다.

- 194줄: column이 3개인 그래프를 만든다. 3개의 그래프에 동일한 scatter를 넣어놓고 각각 다른 회귀예측선을 시각화한다. 학습이 잘 이루어졌는지를 확인하기 위해 175줄의 X_test값을 넣어서 y값이 어떻게 나오는지 확인한다.

- Regression의 종류와 parameter에 따라 회귀모델 그래프(예측값)가 달라진다. DecisionTree Regression은 split되어 분류된 값들의 평균값이므로 계단식의 그래프가 나타난다.

'살콤아내 자기계발 > 파이썬' 카테고리의 다른 글
| 파이썬머신러닝완벽가이드 6주차 (353pg. 캐글 주택 가격: 고급회귀 기법) (0) | 2021.06.03 |
|---|---|
| 파이썬머신러닝완벽가이드 6주차 (342pg. 자전거대여수요예측) (0) | 2021.06.02 |
| 파이썬 머신러닝 완벽가이드 6주차 정리 (303pg, 보스턴 주택 가격 예측, 다항회귀) (0) | 2021.05.28 |
| 파이썬 머신러닝 완벽가이드 6주차 정리 (290pg, 회귀 아달린) (1) | 2021.05.26 |
| 파이썬 온라인 교육 플랫폼_코드스테이츠, 정보통신진흥원NIPA, POSTECH MOOC (0) | 2021.05.25 |