캐글에서 train.csv 파일을 내려받은 후 house_price.csv로 저장한다.
https://www.kaggle.com/c/house-prices-advanced-regression-techniques/data
House Prices - Advanced Regression Techniques
Predict sales prices and practice feature engineering, RFs, and gradient boosting
www.kaggle.com

- 94줄: house_info( )로 정보를 확인. 몇몇 비어있는 값들(null)을 볼 수 있다.

참고) Pandas.DataFrame형태에서 하나의 Column에는 동일한 datatype을 가져야 한다.
test= house_df.dtypes 로 확인

- 102줄: isnull_series에는 house_df가 isnull( )에 해당되는 불린값의 element가 들어오며, 이 element의 개수를 sum한다.

- 100줄: 데이터세트 shape, 전체 feature의 type, null 컬럼과 건수를 알 수 있다.

- 114줄, 124줄: 원본 'Sale Price' 그래프와 log화시킨 'Sale Price'그래프 비교

- 122줄: 확실히 log화 시킨 그래프가 편향성이 제거되었음을 볼 수 있다.

- 138줄: 숫자형 null값을 평균값으로 대체했는데, string값의 null값은 평균값으로 대체될 수 없다. (레이블인코딩을 하거나 drop하거나 int나 float형으로 변환시켜서 평균값으로 넣는 방법을 찾아봐야 함.)
- 139줄: fillna는 각 column별 평균값의 시리즈를 null값 안에 자동으로 채워준다. (object, 즉 string을 제외한 값)
- 142줄: house_df의 어떤 column안에서 null값이 1개 이상있다면 (불린값) 이 feature들의 수를 합쳐서 표시한다. (즉, 각 column의 null값의 합을 표시한다)
참고) 아래 코드만 따로 F9로 실행해야함




- 152줄: get_dummies는 원-핫 인코딩을 말한다. 고유값을 뽑은 다음 이 값들을 column에 있는 경우는 1, 없는 경우를 0으로 변환한다.


- 219줄: 회귀계수를 뽑아서 그 index값으로 column이름을 넣는다. 내림차순으로 정렬 후 상위10개, 하위 10개를 각각 coef_high와 coef_low에 담는다.

원-핫 인코딩을 수행 한 뒤 모델 학습될 데이터가 271개로 바뀐다. 이를 각각 10개씩 컬럼명을 시각화한다.

- 242줄: coef_concat는 coef_high, coef_low로 결합한다.

- Ridge와 Lasso 회귀계수보다 LinearRegression의 회귀계수가 더 크다.

- 5Fold 교차검증


- 283줄: GridSearchCV
Ridge와 Lasso에 alpha값을 주어 최적의 alpha값을 찾는다. (교차검증기반이므로 train데이터를 사용)



- 교차검증 후 Lasso의 퍼포먼스가 가장 개선되었음을 볼 수 있다.
- 365pg. skew
skew값이 1이상이면 왜곡정도가 높다고 판단하지만 상황에 따라 편차가 있다. skew( )를 적용하는 피처에서 원-핫 인코딩된 카테고리 숫자형 피처는 제외해야 한다. 이와 같은 이진분류값은 0과 1뿐인 값을 가지므로 skew값이 높기 때문이다.
- 328줄: house_df는 원-핫 인코딩되지 않은 원본데이터이다. object 데이터 타입인 columns을 제외한 나머지 column이름을 index에 넣어준다.
- 331줄: house_df[features_index] 데이터프레임에 lamda함수를 적용한다. x는 axis값에 따라 달라진다. (aixs=0은 column방향, axis=1은 row방향으로 axis=0이 기본값이다) 즉, skew_features에는 각 column의 skew값이 들어간다.
참고) skew(x) 계산: column방향(axis=0)의 데이터가 들어가야 함. (한 column의 데이터 분포를 보기 위함이므로)
- 334줄: skew_features_top에는 skew값이 1이상인 값들의 시리즈가 들어간다. (이렇게 편향된 데이터 시리즈를 병렬하거나 정렬해야 함)


- 343줄: skew_features_top을 로그변환 함
- 350줄: 로그변환 후 다시 원-핫 인코딩 적용 (데이터전처리 후 다시 최적의 alpha parameter값을 찾음)

새로운 최적 alpha값이 나옴

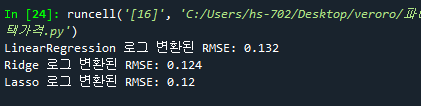
- 365줄: 데이터 전처리 후 Ridge와 Lasso의 RMSE값이 달라짐. (개선됨)


- 387줄: 로그변환하여 데이터전처리한 값들의 scatter 값을 본다.

- 그래프에서 보았듯이 outlier만 재고하면 훨씬 더 좋은 성능을 가질 수 있다.

- 405줄: GrLivArea가 4000이상이고 SalePrice가 500000보다 작은 outlier인 index를 outlier-index에 넣는다.

- 412줄: outlier의 인덱스 4 정보를 row방향으로 삭제한다.
- 421줄: 새롭게 alpha값을 구한다

- 432줄: 최적화 된 alpha값으로 학습, 테스트데이터 예측/평가 수행

점점 성능이 좋아지는 것을 볼 수 있다.

- XGBoost와 LightBGM 학습/예측/평가


- 트리 회귀 모델의 피처 중요도 시각화


- 371pg. 회귀모델의 예측 결과 혼합을 통한 최종 예측
개별 회귀 모델의 예측결과값을 특정 비율로 혼합해서 최종 회귀값을 예측한다. (성능이 더 좋은 쪽에 가중치를 더한다. Lasso가 성능이 더 좋아서 가중치를 더 줌)


- 373pg. 스태킹 앙상블 모델을 통한 회귀 예측
스태킹: 여러개의 esetimator를 점점 쌓아서
KFold는 교차검증용 데이터를 split하는 index를 반환한다. (cross_val_scores와 차이)
- 569줄: train_fold_pred는 1166x1의 2차원 shape에 np.zeros로 0으로 채운다.
- 570줄: test_pred에는 262x5의 2차원 shape에 np.zeros로 0으로 채운다.
- 574줄: 스태킹은 1166의 데이터를 5등분 한 뒤 차례차례 5차 교차검증한다. (검증1/트레인4 비율로 나눠서)
- 583줄: valid_index(검증데이터 1묶음)을 train_fold_pred에 교차검증된 값을 차곡차곡 쌓는다. (for문을 5번 돌림)
- 585줄: 전체 row와 folder_counter (0,1,2,3,4) test_pred에 모델 예측값을 차곡차곡 채워넣는다.

- 588줄: test_pred를 평균화해서 262x1 행렬로 만든다.
- 604줄: 이와 같은 행위를 4개의 각각의 모델에 실행시킨다.

- 이 코드를 실행시키면 다음과 같은 Error가 생기므로 567줄의 Shuffle을 True로 바꾸거나 random_state값을 바꿔준다.
kf = KFold(n_splits=n_folds, shuffle=False, random_state=0)


즉 1166x4, 262x4의 데이터가 만들어진다. 아래 이를 Stack_fianl_X_train, Stack_fianl_X_test로 최종학습 시킨다.

'살콤아내 자기계발 > 파이썬' 카테고리의 다른 글
| 파이썬 머신러닝완벽가이드 7주차_최종실습 (0) | 2021.06.08 |
|---|---|
| 파이썬머신러닝완벽가이드 6주차 (353pg. 캐글 주택 가격_추가코드) (0) | 2021.06.04 |
| 파이썬머신러닝완벽가이드 6주차 (342pg. 자전거대여수요예측) (0) | 2021.06.02 |
| 파이썬 머신러닝 완벽가이드 6주차 정리 (319pg, 규제선형모델-릿지, 라쏘, 엘라스틱넷, 로지스틱회귀) (0) | 2021.05.31 |
| 파이썬 머신러닝 완벽가이드 6주차 정리 (303pg, 보스턴 주택 가격 예측, 다항회귀) (0) | 2021.05.28 |