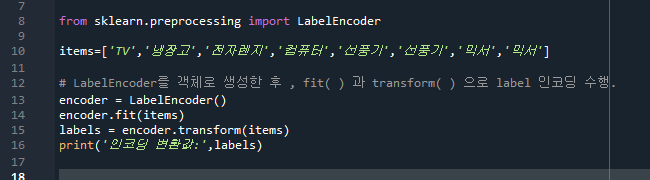
118pg. 데이터 전처리 (Data Preprocessing) - Null, NaN값(결손값)은 허용되지 않으므로 고정된 다른 값(평균값 등)으로 변환한다. Null값이 대부분이라면 해당 feature는 drop한다. - 사이킷런 ML알고리즘은 문자열을 입력값으로 허용하지 않으므로 숫자형으로 변환하거나 불필요한 경우 삭제한다. (feature vectorization) 데이터 인코딩 - Label encoding: 카테고리 feature를 코드형 숫자값으로 변환 (1, 2, 3...) - One Hot encoding: 고유 값에 해당하는 Column에만 1을 표시, 나머지는 0 Label Encoding encoder는 클래스 LabelEncoder( )의 인스턴스다. items안의 string 값의..