39pg
판다스(Pandas)
- 넘파이 기반으로 작성되었고 넘파이보다 고수준 API를 제공한다. 칼럼을 분리한 파일, CSV파일 등을 DataFrame타입으로 변경해 사용가능하다.
* API: application programming interface
- 판다스는 주로 행과 열로 이루어진 2차원 데이터 DataFrame을 핵심개체로 한다. (Series 데이터타입도 제공함)
- Series와 DataFrame은 모두 Index를 key값으로 가지고 있다.
- Series는 칼럼이 하나인 데이터구조이지만 (1차원데이터) DataFrame은 칼럼이 여러개로 이루어진다. (즉 DataFrame은 여러개의 Series로 이루어졌다고 말할 수 있다.=2차원 데이터)
1. Titanic 실습
아래 홈페이지에서 train.csv 파일을 다운받으시오.
Titanic - Machine Learning from Disaster
Start here! Predict survival on the Titanic and get familiar with ML basics
www.kaggle.com
Variable explorer로 볼 수 있도록 데이터를 호출하시오

print(titanic_df.info()) 의 결과값을 보면 다음과 같은 사실을 알 수 있다.

- non-null: 비어져 있지 않은 데이터 수가 891개이다. shape의 형태를 보고 몇개의 null값이 있는지 본다. age, cabin에 값이 누락되어 있음을 볼 수 있다. 이를 감안해서 데이터분석을 해야한다.
- column에서 생존률과 관련된 유의미한 정보만 뽑아서 machine learning을 하면 정확도가 높아진다.
- 하나의 column은 동일한 데이터 타입으로 구성되어야만 한다. (object는 string으로 생각하면 된다)
temp[]대신에 info(), describe() 함수를 사용해서 데이터를 불러온다.


-min, 25%, 50%, 75%, max는 사분위값을 말한다.
-value.counts( )
Index 자리에 있는 것은 Pclass의 유니크한 값이다.(단일값) 각각의 값이 몇개가 있는지 value.count를 이용해 알 수 있다.


-test2를 만들어 datatype을 본다. 891개의 series 데이터 타입이다. Pclass의 값을 보면 1,2,3으로 구성되어 있음을 알 수 있다.


49pg 코드 따라하기


df_array1과 df_list1의 차이는 없다. (넌파이와 판다스형 데이터 타입)


TIP: 데이터프레임 형태에서 column 1개를 가진 것과 series와는 차이가 있다.
50pg. 2x3행렬 DataFrame만들기
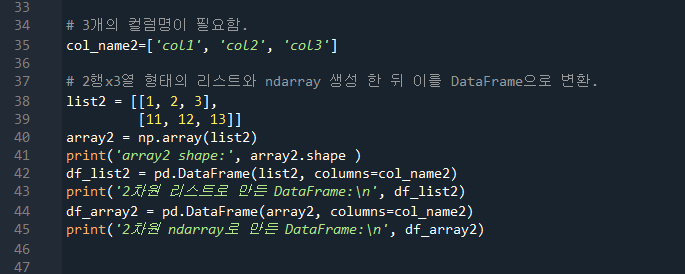


51pg. DataFrame에서 바로 list로 갈 수 없으므로 value값을 통해 ndarray로 전환시키고 이를 list화 시킬 수 있다.
즉, list3=df_dict.tolist( ) 이렇게 쓸 수 없음.
>> df_dict.values.tolist( ) 로 리스트화 해야함.
list에서 dictionary 전환 호출 메서드는 to_dict( )다.


- col1:[1,11] 이 쌍이 key:value 값이다. 만약 col1:[1,11,111] 이렇게 추가가 된다면 row2가 아래에 추가로 생성된다.


52pg Column 데이터 생성/수정

- Parch는 parents children을 의미
- age_by_10의 데이터타입 return값은 series이다
- .head( )는 위에서부터 3개의 row를 의미함. 평소 spider편집툴을 쓸 때는 head를 잘 쓰지 않지만, 다른 편집툴에서 필요한 경우 head정보를 출력하기 위해 .head( )를 사용한다.

55pg Column 삭제

tianic_df의 column 한 개가 제거되었다.

만약 다음과 같이 코드를 추가해보자

인덱스 8에 해당하는 row가 사라지는 것을 볼 수 있다.


56pg. inplace=True
inplace 파라미터 설정을 통해 값을 return하지 않고 원본데이터 자체를 바꿀 수 있다.
Age_0, Age_by_10, Family_No 가 사라졌다. (axix=1은 열을 말함)


57pg. Index 객체
- DataFrame, Series의 레코드를 고유하게 식별하는 객체이다.
- DataFrame.index, Series.index 속서을 통해 객체추출가능
다음과 같이 1차원 데이터타입 (series)를 추출해보자



코드추가
indexes_value=indexes.values

DataFrame에서 index를 이용해서 해당 DataFrame의 index정보를 출력할 수 있다. 이 출력된 정보는 ndarray타입이 아니라 range index(인덱스를 표기하기 위한 고유한 데이터타입)이 된다.

index객체의 슬라이싱도 가능하다.


하지만 index객체는 개별 row를 구분하는 고유값이기 때문에 다음과 같이 변경할 수 없다.
indeexes[0]=5 >> 불가능!!
59pg. 'Fare'를 series값으로 따로 불러내어보자. 최대값, 최소값, 합계 등을 구할 수 있다.



60pg. reset_index( )
인덱스가 연속된 int형 데이터가 아닐 경우 이를 연속 int형 데이터로 만듦. (이 때, DataFrame데이터 형식으로 반환됨)
- Series의 value.counts( )는 Pclass의 고유값이 식별자 인덱스를 함.
- Sereis의 reset.index( )는 새롭게 연속숫자형(int형) DataFrame을 반환. 이 때 reset_index( ) parameter 중 drop=True로 설정하면 기존 인덱스는 새로운 칼럼으로 추가되지 않고 삭제(drop)됨. 아래예시에서는 false를 사용해서 새로운 Column이 추가됨.


'살콤아내 자기계발 > 파이썬' 카테고리의 다른 글
| 파이썬 머신러닝 완벽가이드 2주차 정리 (타이타닉실습 2_isnan, groupby) (0) | 2021.04.23 |
|---|---|
| 파이썬 머신러닝 완벽가이드 1주차 정리 (판다스 60pg~, 타이타닉 실습) (0) | 2021.04.23 |
| 파이썬 머신러닝 완벽가이드 1주차 정리 (넘파이 15pg~38pg) (0) | 2021.04.21 |
| 점프투파이썬 3주차 실습_서로 유사한 모양(인구분포)의 그래프를 가진 동을 찾아라 (0) | 2021.04.20 |
| 점프투파이썬 3주차 실습_시간별 승하차인원 (0) | 2021.04.20 |