61pg. 데이터 셀렉션 및 필터링 (.ix, .loc, iloc)
DataFrame['칼럼명']과 같이 리스트 객체를 이용해서 원하는 데이터를 추출한다.
Ex) titanic_df['Pcclss'].head(3)
head(3)은 헤더정보를 3줄까지 추출한다는 의미
추가) titanic_df[0:2]과 같이 인덱스 슬라이싱을 이용해서 원하는 데이터를 추출할 수 있다.
추가) titanic_df[ titanic_df['Pclass']=3].head(3)과 같이 불린 인덱싱 표현으로 추출할 수 있다.
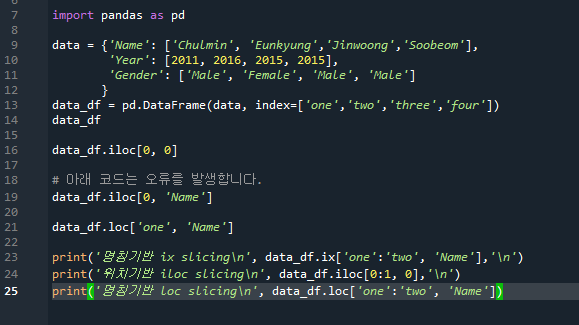
66pg. 명칭 기반(label) 인덱싱과 위치 기반(position) 인덱싱
참고) .ix는 더 이상 파이썬에서 제공되지 않는다
- 명칭기반 인덱싱: 칼럼의 명칭을 기반으로 위치지정 >> DataFrame의 인덱스값, loc[ ]
Ex) data_df_reset.loc['one', 'Name'] >>> 인덱스값이 one인 행의 Column명이 'Name'인 데이터를 추출
참고) loc[ ] 슬라이싱 적용시 시작값~종료값까지 포함한다. (일반 슬라이싱 할 때 -1위치를 포함하는 것 과는 다름. 명칭기반은 숫자형이 아닐 수도 있기 때문)
- 위치기반 인덱싱: 0을 시작으로 하는 가로/세로 축의 좌표를 기반으로 위치치정, iloc[ ]
Ex) data_df_reset.iloc[0,1] >>> 첫번째 행(0)과 두번째 열(1)의 위치에 있는 값을 반환

72pg. 불린 인덱싱
Boolean: 불 방식의(특히 컴퓨터와 전자공학에서 참과 거짓을 나타내는 숫자 1과 0만을 이용하는 방식)

원본데이터 인덱션 포지션에 불린 인덱싱을 하고 Name과 Age column을 뽑아냄.

[ [ 'Name', 'Age' ] ] 이렇게 대괄호를 두개넣는 이유: 여러개의 Column을 넣기 위해 (해당 Column을 리스트형식으로 넣어야 함)

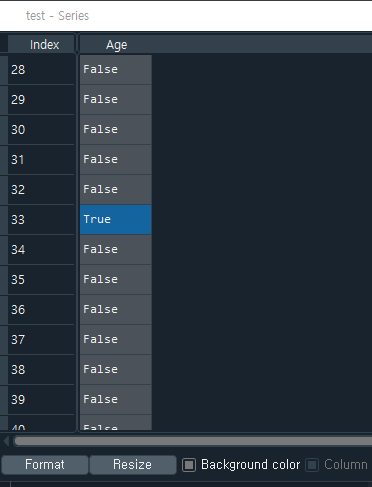
Boolean값에 대해 조건식을 만족하는 데이터 추출하기


각각의 변수의 데이터타입은 다음과 같다

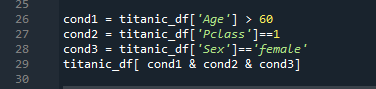
cond1, cond2, cond3은 Series 데이터타입의 Boolean값을 가진다.

그리고 test4와 test5s의 결과값은 같다.

75pg. 정렬 Aggregation함수, GroupBy 적용
- sort_values( ) 메서드 이용
Ex) taitanic_sorted = titanic_df.sort_values(by=['Name'])
- sort_value( ) 메서드의 parameter는 by(특정Column으로 정렬), ascending(True:오름차순, False:내림차순), inplace(False: DataFrame 원본을 유지한 체 정렬된 DataFrame을 결과로 return한다) 이다.

다음과 같이 이름순(알파벳순)으로 정렬된 것을 볼 수 있다.

이번에는 Pclass와 Name Column을 기준으로 정렬한다. (by)


질문) 'Pclass'는 오름차순, 'Name'은 내림차순으로 정렬하려면 어떻게 해야할까? (질문해야함)
76pg. aggregation함수
aggregation: 집적, 집합의 뜻
min, max, sum, count 등이 있다.

null값이 아닌 Age, Fare의 평균(mean)을 구한 값은 다음과 같다.

참고) ' ', [ ] 는 none값이 아니라 엄밀히 말하면 string과 비어있는 list이다. none은 데이터가 없음이지 값이 0임을 의미하지 않는다.
77pg. Groupby( )를 적용해보자
Ex) titanic_groupby=titanic_df.groupby(by='Pclass')
참고) groupby(by='Pclass') 또는 groupby('Pclass') 이렇게 둘 다 쓸 수 있다.



데이터 타입의 결과값

Groupby함수 자체는 의미가 없으나 aggregation함수와 함께 쓰면 달라진다. (77pg)
Ex) titanic_groupby=titanic_df.groupby('Pclass').count()

Object였던 데이터타입이 DataFrame 데이터타입으로 바뀌었다.



Groupby함수의 결과값을 프린트 해 보자



- titanic_df를 Pclass로 groupby하고 Age Column의 max, min값을 구해보자 (.agg는 동시에 여러개의 aggregation함수를 사용할 수 있게 한다)


- Age에서는 max, SibSp에서는 sum, Fare에서는 mean 함수를 각각 적용시켜보자. (딕셔너리 데이터타입으로 쓴다)



79pg. 결손데이터 처리하기

test7은 각 요소에 null값이 있는지 알아보는 boolean값이 있는 dataframe 데이터타입이다.

insa( )에 sum( )함수를 적용하면 각 Column별로 요소들의 value값(null값의 수., 결측치)을 더한 값이 출력된다.


80pg. fillna( )로 결손데이터 대체하기
'Cabin' Column의 빈 값을 C000으로 대체한다.


'Age' Column의 빈 값을 Age의 평균값으로 대체한다.
'Embarked' Column의 빈 값을 'S'로 대체한다.


이렇게 모든 Column을 대상으로 null값이 없도록 만들었다.
82pg. apply lambda식으로 데이터 가공
lamda_square함수: input x값을 제곱한 결과를 output으로 return하시오.


참고) 점프투파이썬 235pg. filter와 map함수
Ex) map(lambda a:a*2, [1,2,3,4,]) >>> [2,4,6,8]
이와 같은 lambda의 기능을 pandas에 적용할 수 있다.

- Input값: 'Name' Column을 순차적으로 x값에 넣어라.
- Output값: 'Name' Column의 개별요소의 string 길이값
- 'Name_Len' Column을 생성

83pg. 'Age' Column값에 다음과 같은 lambda 함수를 적용하시오.

'Age' Column의 값이 15 이하이면 Child라는 결과값을 출력하고, 그렇지 않으면 Adult 결과값을 출력해라.
또한 'Child_Adult' Column을 하나 생성해라.

- 15세 이하는 Child, 60세 이하는 Adult, 그렇지 않으면 Elderly로 표시하시오
(참고: 역슬러시를 하면 한줄코드로 인식됨)
- 'Age_cat' Column 생성


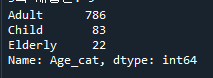
85pg. 나이에 따라 세분화된 분류를 수행하는 함수 생성
사용자정의함수 def를 lambda로 적용하기


'살콤아내 자기계발 > 파이썬' 카테고리의 다른 글
| 파이썬 머신러닝 완벽가이드 2주차 정리 (사이킷런 87pg~, ) (0) | 2021.04.27 |
|---|---|
| 파이썬 머신러닝 완벽가이드 2주차 정리 (타이타닉실습 2_isnan, groupby) (0) | 2021.04.23 |
| 파이썬 머신러닝 완벽가이드 1주차 정리 (판다스 39pg~), 타이타닉 실습 (0) | 2021.04.22 |
| 파이썬 머신러닝 완벽가이드 1주차 정리 (넘파이 15pg~38pg) (0) | 2021.04.21 |
| 점프투파이썬 3주차 실습_서로 유사한 모양(인구분포)의 그래프를 가진 동을 찾아라 (0) | 2021.04.20 |